
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 | |
| | | | | | | | | | | | | | | | | | | | | |
| MSAPSTLPPGGEEGLGTAWPSAANASSAPAEAEEAVAGPGDARAAGMVAIQCIYALVCLVGLVGNALVIFVILRYAKMKTATNIYLLNLAVADELFMLSVPFVASSAALRHWPFGSVLCRAVLSVDGLNMFTSVFCLTVLSVDRYVAVVHPLRAATYRRPSVAKLINLGVWLASLLVTLPIAIFADTRPARGGQAVACNLQWPHPAWSAVFVVYTFLLGFLLPVLAIGLCYLLIVGKMRAVALRAGWQQRRRSEKKITRLVLMVVVVFVLCWMPFYVVQLLNLFVTSLDATVNHVSLILSYANSCANPILYGFLSDNFRRFFQRVLCLRCCLLEGAGGAEEEPLDYYATALKSKGGAGCMCPPLPCQQEALQPEPGRKRIPLTRTTTF | |
| CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCSSSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCHHHHHHHHHHHHHCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC | |
| 9999889999866666778888878888776554345765542188988999999999999866885412210388888799999999999999999967999999971898887667868999999999999999999999848887511643336568889998899999999999899998067894799768980789957899999999999989999999999999999997375788742010010340433568999999999879999999999987899999999999999999799999998099999999999605247873788777777776751012589988648998876688899999988876688889 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 | |
| | | | | | | | | | | | | | | | | | | | | |
| MSAPSTLPPGGEEGLGTAWPSAANASSAPAEAEEAVAGPGDARAAGMVAIQCIYALVCLVGLVGNALVIFVILRYAKMKTATNIYLLNLAVADELFMLSVPFVASSAALRHWPFGSVLCRAVLSVDGLNMFTSVFCLTVLSVDRYVAVVHPLRAATYRRPSVAKLINLGVWLASLLVTLPIAIFADTRPARGGQAVACNLQWPHPAWSAVFVVYTFLLGFLLPVLAIGLCYLLIVGKMRAVALRAGWQQRRRSEKKITRLVLMVVVVFVLCWMPFYVVQLLNLFVTSLDATVNHVSLILSYANSCANPILYGFLSDNFRRFFQRVLCLRCCLLEGAGGAEEEPLDYYATALKSKGGAGCMCPPLPCQQEALQPEPGRKRIPLTRTTTF | |
| 4654442314343323331333323132334344321334313200000002201200220131110000000103321000000000001000000000000000001421100300110010013100100000000002000000000020232122110000000001000000000000020242763310101030236202200100101301221010002000000110232444443444434220000000000000000022100000000014301100100000000200010000000004401410140032212234444445443343444434355454444443434544344643445132354246 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 | | | | | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCSSSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCHHHHHHHHHHHHHCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC MSAPSTLPPGGEEGLGTAWPSAANASSAPAEAEEAVAGPGDARAAGMVAIQCIYALVCLVGLVGNALVIFVILRYAKMKTATNIYLLNLAVADELFMLSVPFVASSAALRHWPFGSVLCRAVLSVDGLNMFTSVFCLTVLSVDRYVAVVHPLRAATYRRPSVAKLINLGVWLASLLVTLPIAIFADTRPARGGQAVACNLQWPHPAWSAVFVVYTFLLGFLLPVLAIGLCYLLIVGKMRAVALRAGWQQRRRSEKKITRLVLMVVVVFVLCWMPFYVVQLLNLFVTSLDATVNHVSLILSYANSCANPILYGFLSDNFRRFFQRVLCLRCCLLEGAGGAEEEPLDYYATALKSKGGAGCMCPPLPCQQEALQPEPGRKRIPLTRTTTF | |||||||||||||||||||||||||
| 1 | 4n6hA | 0.41 | 0.37 | 0.85 | 2.90 | Download | IDDALKLANEGKVKEAQAAAEQLKTTAYIQKYLGSPGARSASSLALAIAITALYSAVCAVGLLGNVLVMFGIVRYTKMKTATNIYIFNLALADALATSTLPFQSAKYLMETWPFGELLCKAVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPAKAKLINICIWVLASGVGVPIMVMAVTRPRDG--AVVCMLQFPSWYWDTVTKICVFLFAFVVPILIITVCYGLMLLRLRSVRLLSGSKEKDRSLRRITRMVLVVVGAFVVCWAPIHIFVIVWTLVDPLVVAALHLCIALGYANSSLNPVLYAFLDENFKRCFRQLCRKPCG--------------------------------------------------------- | |||||||||||||||||||
| 2 | 4n6hA | 0.45 | 0.37 | 0.76 | 3.94 | Download | ---------------------------------GSPGARSASSLALAIAITALYSAVCAVGLLGNVLVMFGIVRYTKMKTATNIYIFNLALADALATSTLPFQSAKYLMETWPFGELLCKAVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPAKAKLINICIWVLASGVGVPIMVMAVTRPRDG--AVVCMLQFPSPSWDTVTKICVFLFAFVVPILIITVCYGLMLLRLRSVRLLSGSKEKDRSLRRITRMVLVVVGAFVVCWAPIHIFVIVWTLVDPLVVAALHLCIALGYANSSLNPVLYAFLDENFKRCFRQLCRK------------------------------------------------------------ | |||||||||||||||||||
| 3 | 4n6hA | 0.45 | 0.36 | 0.76 | 3.84 | Download | ----------------------------------SPGARSASSLALAIAITALYSAVCAVGLLGNVLVMFGIVRYTKMKTATNIYIFNLALADALATSTLPFQSAKYLMETWPFGELLCKAVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPAKAKLINICIWVLASGVGVPIMVMAVTRPRDG--AVVCMLQFPSWYWDTVTKICVFLFAFVVPILIITVCYGLMLLRLRSVRLLSGSKEKDRSLRRITRMVLVVVGAFVVCWAPIHIFVIVWTLVDPLVVAALHLCIALGYANSSLNPVLYAFLDENFKRCFRQLCRKPCG--------------------------------------------------------- | |||||||||||||||||||
| 4 | 2ziy | 0.21 | 0.24 | 0.91 | 1.54 | Download | -------DLR----DNETW--WYNPSI---IVHPHWREFDQVPDAVYYSLGIFIGICGIIGCGGNGIVIYLFTKTKSLQTPANMFIINLAFSDFTFSLGFPLMTISCFLKKWIFGFAACKVYGFIGGIFGFMSIMTMAMISIDRYNVIGRPMAASKKMSHRRAFIMIIFVWLWSVLWAIGPIFGWGAYTL-EGVLCNCSFDYISRDTTRSNILCMFILGFFGPILIIFFCYFNIVMSVSNHEKEMAAQAGANAEMRLAKISIVIVSQFLLSWSPYAVVALLAQFGPLVTPYAAQLPVMFAKASAIHNPMIYSVSHPKFREAISQTFPWVLTCCQFDDKETEDDKDA-----------ETEIPAGESSDAAP----SADAAQMKE---- | |||||||||||||||||||
| 5 | 4djh | 0.43 | 0.34 | 0.73 | 1.19 | Download | ------------------------------------------SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKMKTATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVREDVDVIECSLQFPDDDWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLSGYREKDRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSA-ALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP------------------------------------------------------------ | |||||||||||||||||||
| 6 | 4n6hA | 0.45 | 0.36 | 0.76 | 3.36 | Download | ------------------------------------GARSASSLALAIAITALYSAVCAVGLLGNVLVMFGIVRYTKMKTATNIYIFNLALADALATSTLPFQSAKYLMETWPFGELLCKAVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPAKAKLINICIWVLASGVGVPIMVMAVTRPRDG--AVVCMLQFPSWYWDTVTKICVFLFAFVVPILIITVCYGLMLLRLRSVRLLSGSKEKDRSLRRITRMVLVVVGAFVVCWAPIHIFVIVWTLVDPLVVAALHLCIALGYANSSLNPVLYAFLDENFKRCFRQLCRKPCG--------------------------------------------------------- | |||||||||||||||||||
| 7 | 4djh | 0.43 | 0.34 | 0.73 | 1.75 | Download | --------------------------------------------AIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKMKTATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVREDVDVIECSLQFPDDDYDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLSGYREKDRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSA-ALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCF------------------------------------------------------------- | |||||||||||||||||||
| 8 | 4n6hA | 0.44 | 0.36 | 0.76 | 5.37 | Download | ------------------------------------GSPGASSLALAIAITALYSAVCAVGLLGNVLVMFGIVRYTKMKTATNIYIFNLALADALATSTLPFQSAKYLMETWPFGELLCKAVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPAKAKLINICIWVLASGVGVPIMVMAVTRPRDGAVVCMLQFPSPSWYWDTVTKICVFLFAFVVPILIITVCYGLMLLRLRSVRLLSGSKEKDRSLRRITRMVLVVVGAFVVCWAPIHIFVIVWTLVDPLVVAALHLCIALGYANSSLNPVLYAFLDENFKRCFRQLCRKPCG--------------------------------------------------------- | |||||||||||||||||||
| 9 | 4n6hA | 0.45 | 0.36 | 0.76 | 3.32 | Download | ----------------------------------SPGARSASSLALAIAITALYSAVCAVGLLGNVLVMFGIVRYTKMKTATNIYIFNLALADALATSTLPFQSAKYLMETWPFGELLCKAVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPAKAKLINICIWVLASGVGVPIMVMAVTRPRDG--AVVCMLQFPSWYWDTVTKICVFLFAFVVPILIITVCYGLMLLRLRSVRLLSGSKEKDRSLRRITRMVLVVVGAFVVCWAPIHIFVIVWTLVDPLVVAALHLCIALGYANSSLNPVLYAFLDENFKRCFRQLCRKPCG--------------------------------------------------------- | |||||||||||||||||||
| 10 | 5c1mA | 0.39 | 0.31 | 0.75 | 3.92 | Download | -------------------------------GSHSLPQTGSPSMVTAITIMALYSIVCVVGLFGNFLVMYVIVRYTKMKTATNIYIFNLALADALATSTLPFQSVNYLMGTWPFGNILCKIVISIDYYNMFTSIFTLCTMSVDRYIAVCHPVKALDFRTPRNAKIVNVCNWILSSAIGLPVMFMATTKYRQGSIDCTLTFSHPTWYWENLLKICVFIFAFIMPVLIITVCYGLMILRLKSVRMLSGSKEKDRNLRRITRMVLVVVAVFIVCWTPIHIYVIIKALITTFQTVSWHFCIALGYTNSCLNPVLYAFLDENFKRCF------------------------------------------------------------------ | |||||||||||||||||||
| ||||||||||||||||||||||||||
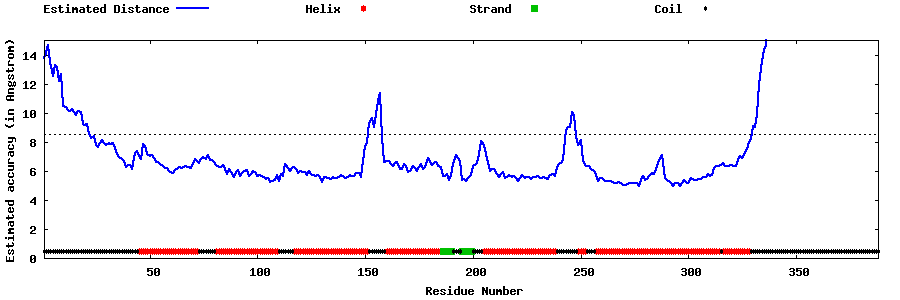
| Generated 3D models | Estimated local accuracy of models | ||
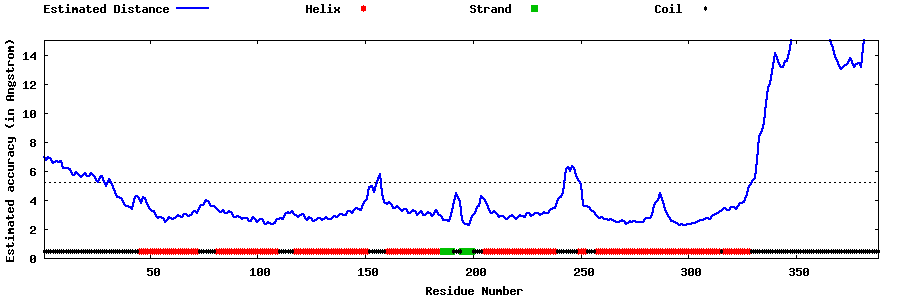 | |||
|
|
|||
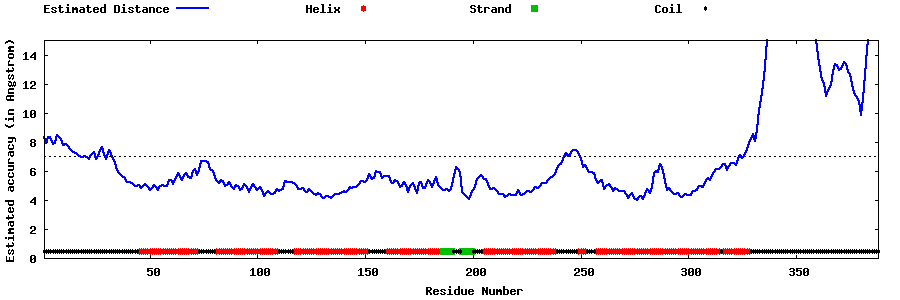 | |||
|
| |||
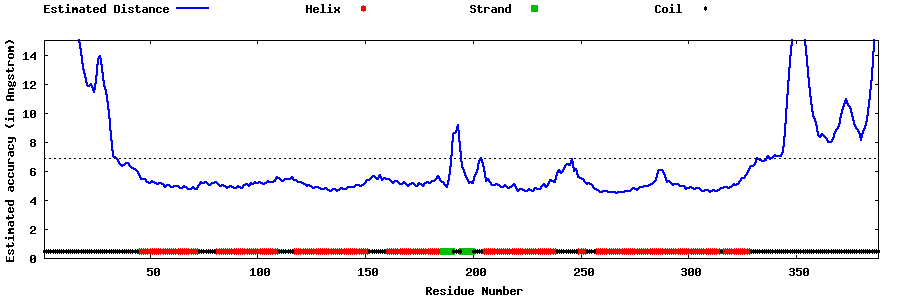 | |||
|
| |||
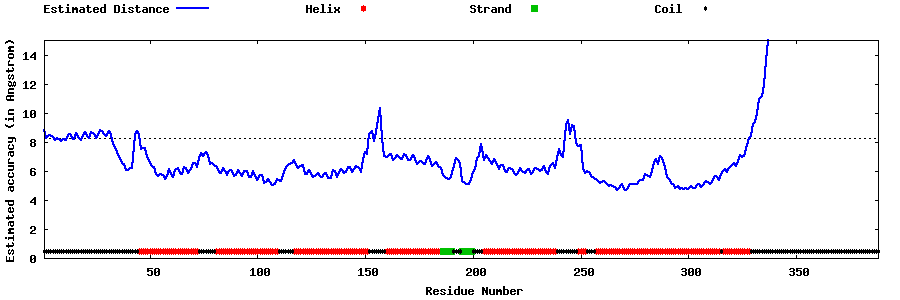 | |||
|
| |||
 | |||
|
| |||
